Abstract
Speech-driven 3D talking head generation aims to produce lifelike facial animations precisely synchronized with speech. While considerable progress has been made in achieving high lip-synchronization accuracy,
existing methods largely overlook the intricate nuances of individual speaking styles, which limits personalization and realism. In this work, we present a novel framework for personalized 3D talking head animation,
namely PTalker. This framework preserves speaking style through style disentanglement from audio and facial motion sequences and enhances lip-synchronization accuracy through a three-level alignment mechanism between
audio and mesh modalities. Specifically, to effectively disentangle style and content, we design disentanglement constraints that encode driven audio and motion sequences into distinct style and content spaces to enhance speaking style
representation. To improve lip-synchronization accuracy, we adopt a modality alignment mechanism incorporating three aspects: spatial alignment using Graph Attention Networks to capture vertex connectivity in the 3D mesh structure,
temporal alignment using cross-attention to capture and synchronize temporal dependencies, and feature alignment by top-$k$ bidirectional contrastive losses and KL divergence constraints to ensure consistency between speech and mesh
modalities. Extensive qualitative and quantitative experiments on public datasets demonstrate that PTalker effectively generates realistic, stylized 3D talking heads that accurately match identity-specific speaking styles, outperforming
state-of-the-art methods.
Proposed Method
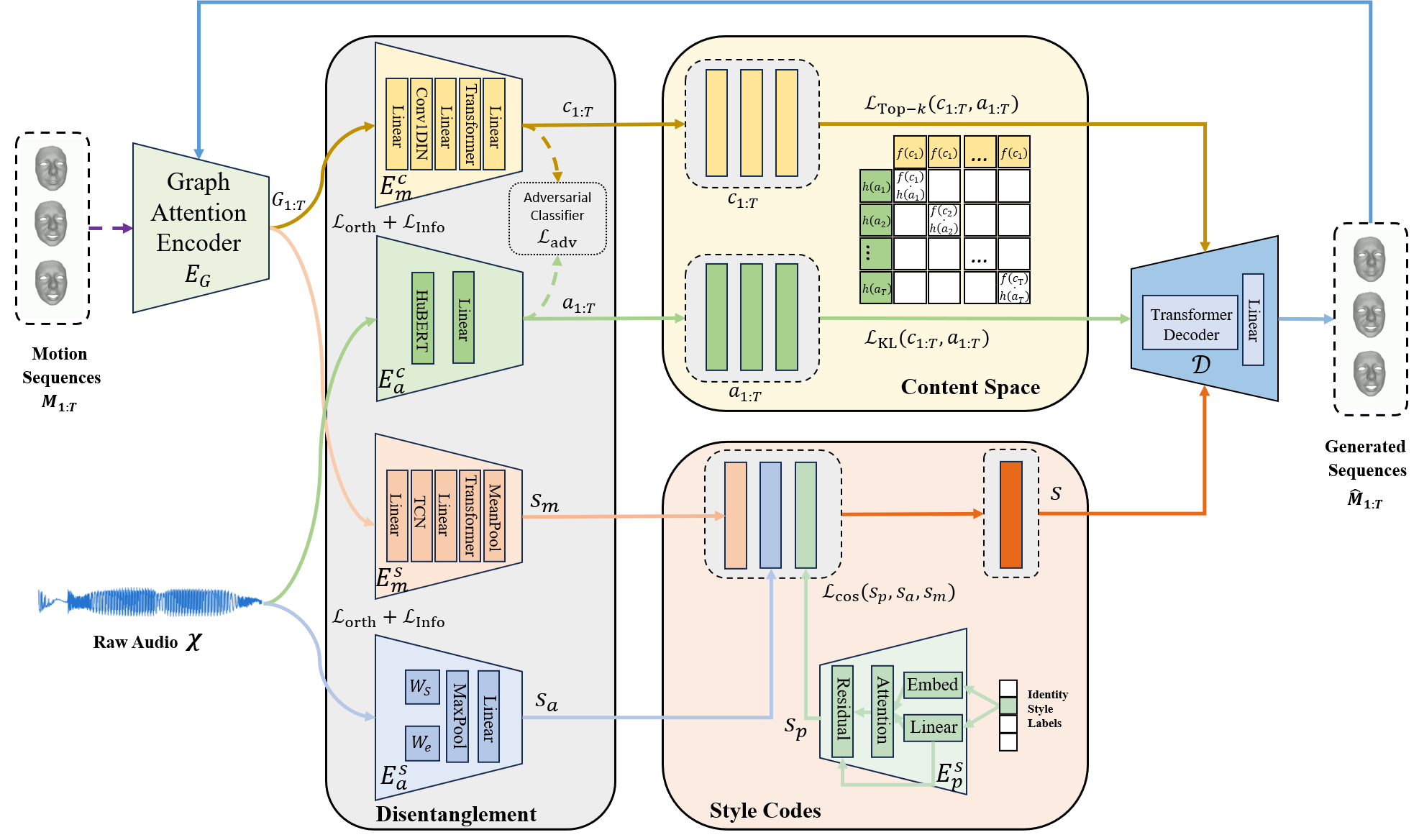
Illustration of the proposed PTalker. The input motion sequence is first encoded by the graph attention encoder. Then, the motion style encoder and the motion content encoder
extract the motion style and content features. The synchronized raw speech is encoded into audio features and audio style by the audio content encoder and the audio style encoder.
The identity style encoder encodes the one-hot vector into the personal style. The motion decoder reconstructs the facial motions.